
Fine to Fabulous: Transforming data for performance & integrity


Backstory:
As you know from my previous posts, I’ve been analyzing data from my blog to provide my readers with a better experience. In the last post in this series, we grouped my readers to differentiate my fans from my skeptics to convert the latter, you can find this here. This time rather we will be optimizing an old solution for performance while maintaining the integrity of the data. What we’ll be doing today will feel like revamping the McDonald’s burger to sell it at Gordon Ramsay’s burger shop, in other words, taking something good and making it perfect. So let’s wake up the perfectionist in you and dive in!
The Problem:
Over the last few posts, we’ve been trying to build a 360 view of our users, by capturing different profiles in our user_profile table to represent our users. This came in handy when we were trying to extend the clickstream data from my blog by identifying and adding user info. We did this by building the user_clickstream view that combines clickstream and profile data. I recommend checking it out if you haven’t already, you can find it here. This approach worked fine for a while but as my blog grows, both clickstream & user_profile tables have been growing and with this, our previous solution just doesn’t cut it anymore. Using the user_clickstream view to do further analysis has been both computationally and time intensive. Hence, we need to optimize this!
The Data:
Here’s a glimpse of the user_clickstream view which combines clickstream and user data that we’re trying to optimize:
+------+---------+------------+-------------+---------+-----+
| date | user_id | profile_id | ip | device | ... |
+------+---------+------------+-------------+---------+-----+
| 1/1 | 123 | xyz | 101.102.1.5 | android | ... |
| 1/1 | 789 | pqr | 101.102.7.7 | ios | ... |
| 1/7 | 456 | abc | 101.102.1.6 | windows | ... |
| 1/10 | 123 | xyz | 101.102.1.5 | android | ... |
| ... | ... | ... | ... | ... | ... |
+------+---------+------------+-------------+---------+-----+STOP! Before reading ahead here’s where I want you to take some time and think about the problem yourself before reading my approach.
My approach:
First, let’s think about why our existing user_clickstream is having problems. One reason is that it only exists in the metaverse with no real significance. Let me explain, the main difference between a view and a table is that in a view the data is built on the fly when it’s used whereas in a table the data is static. Hence using a view in a complex query may increase the computation since now you’re also computing the view. In our case, as the underlying source data grows, keeping user_clickstream a view may no longer be the best option.
So can we make user_clickstream a table then? To answer this first let’s dive in deeper. The user_clickstream view now basically identifies the user in the clickstream data using the user_profile data. Here the clickstream table is what we call a fact table with event records to which data gets added with a row for a user’s every click. Whereas our user_profile is a dimension table with a single row for every user having their latest & greatest info. If you think about it, our user_clickstream is a fact table too, that looks a lot like the clickstream table but with user info.
One way to make it a table is to perform the user matching in batches and store the result in a table. We can pick a day’s worth of data from clickstream table add user info from user_profile and dump the results into a user_clickstream table which is partitioned by day.
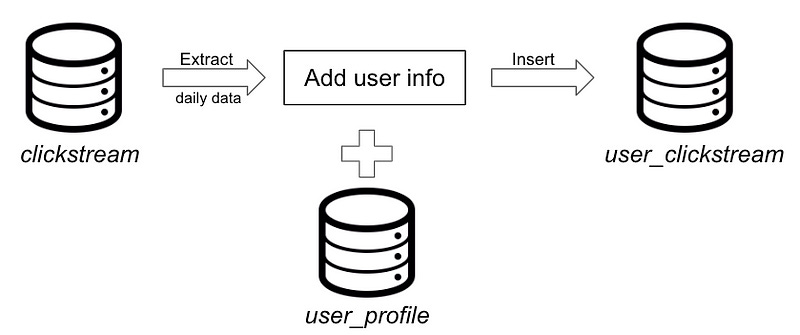
Here’s what this looks like in SQL:
INSERT INTO user_clickstream
-- Batch of clikstream data
WITH daily_clickstream AS (
SELECT *
FROM clickstream
WHERE date = CURRENT_DATE()
)
-- Identify & add user info
SELECT up.user_id, up.profile_id, clk.*
FROM daily_clickstream AS clk
LEFT JOIN user_profile AS up
LEFT JOIN UNNEST(web) AS wb
ON clk.ip = wb.ip
AND clk.mac_id = wb.mac_id
AND ...Now, this does get us a static table but we are forgetting that a user’s profile evolves as we learn more about our users which may result in a profile moving to another user, I talk about this more here. Given this, a drawback of the above approach is that since it’s not a view anymore, which is built on the fly, the data in the table is not updated with the user’s most latest info making it stale. Hence to maintain the integrity of the data, we may want a way to update this table with the user's latest info.
This update can be done in two ways, the easier way to do this is to redo the above approach of matching the user in batches and rather than inserting, replace the data in the user_clickstream table. For example, if I want to update the user_clickstream for the past year, I’d alter the above query to extract source data from last year, redo the matching with the latest info and then merge it into our existing user_clickstream table.
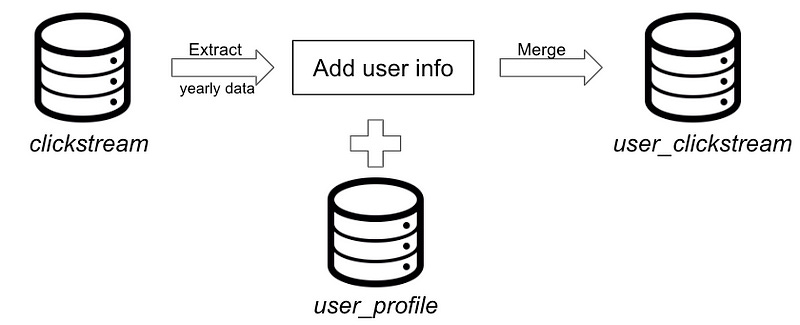
The drawback of this is that it’s heavily reliant on the source and is redundant because you’re also processing users that don’t have any updates in their profiles.
What if we could only do this for profiles that have updates? That’s the second approach, to do this we’d need to know profiles that have an update. Luckily if you recollect from my past blog we already developed this, see here. We can leverage this output to only update profiles that have a new user_id. Assuming we have this output in a history table called profiles_to_merge_hist. Let’s take an example for the above data:
+------+---------------+-------------------+
| date | final_user_id | profiles_to_merge |
+------+---------------+-------------------+
| 1/10 | 123 | [abc,xyz] |
| ... | ... | ... |
+------+---------------+-------------------+From this, we see that the profiles abc and xyz now belong to user_id=123. The next step is to go back and update user_clickstream with this info. Here’s how you do this in SQL:
MERGE INTO user_clickstream AS target
USING (
-- New changes in profile
SELECT final_user_id, merged_profile_id
FROM profiles_to_merge_hist
LEFT JOIN UNNEST(profiles_to_merge) merged_profile_id
WHERE date = CURRENT_DATE()
) AS source
-- Matched on existing profile_id
ON target.profile_id = source.merged_profile_id
-- To update user_id
WHEN MATCHED THEN
UPDATE SET target.user_id = source.final_user_idHere we pick the latest profile changes from profiles_to_merge_hist, match on profile_id and update the user_id with the final_user_id. And finally, we have a way to make user_clikstream a static table for better performance but also maintain data integrity by keeping it updated with the latest user info. This time updating user_clickstream was straightforward given we only had to update the user_id but what if we add more attributes? This is something we’ll be exploring next time so make sure to subscribe here to not miss it.
Food for thought:
If not a table, what else could user_clickstream be?
Why partition the user_clickstream by day? What benefit does this have?
How do we make merging process feed user_clickstream updates directly?
If you want to avoid the MERGE operation, what do you do?

Let me know how you’d approach it. If you found this helpful, share it. If you’re into this, you can find me on Twitter @abhishek27297 where I talk data. If you don’t want to miss my next post, consider subscribing here. It’s free and you’ll be notified when I post my next blog.