
Stream, Store, and Analyze: Building a Data-Driven Suggestion Box with Kafka & SQL


Introduction:
Have you ever wondered how to efficiently capture and analyze data from a source that continuously produces valuable information? Well, this is what we’ll cover in today’s blog where I build a robust solution to capture reader feedback for my blog leveraging Apache Kafka and sophisticated data architecture. To foster a stronger connection with my readers, I’ve implemented a “suggestions box” like the one below that allows my readers to provide feedback. Imagine a community-driven platform that grows stronger with every suggestion.

The data architecture we build will help me captures these suggestions, record my progress, and finally helps me prioritize suggestions by segregating avid readers from bots. This not only enhances the overall quality of the blog but also strengthens the bond between me and my readers. If this sounds exciting, you may want to check out my previous post here wherein I use machine learning to go from mass emailing to a targeted email campaign.
Learning Objectives:
Understand how to architect a data-driven suggestion box using Apache Kafka, python and SQL, enabling seamless capturing, storing, and analysis of data.
Learn best practices for designing data pipelines using history and current tables.
Walkthrough an example of using Arrays in SQL to efficiently store data.
Data Architecture
Let’s start by thinking about how we can get the data from the form to a table we can use. Whenever a reader submits a suggestion, it is recorded as a JSON message. While a straightforward approach would be to build a script to directly add these messages to a table, this method can become cumbersome and difficult to scale. To overcome this challenge, we turn to Kafka.
Kafka acts as a robust streaming platform, facilitating efficient communication between data sources and listeners(users). It allows us to publish these suggestion messages to a specific topic, and imagine a river of data flowing downstream. At the other end, we have listeners who can access and consume these messages at any time as they line up in the order of occurrence. For our scenario, we choose to process the suggestions in batches, reviewing them on a daily basis for further analysis. Depending on your use case you can read these messages as they come in(streaming) or on a dedicated schedule(batch). For our scenario, I’ll opt for batch processing as I plan on reviewing them on a daily basis for further analysis.
Now, let’s consider how we store this data. A simple solution would be to add the suggestions to a single table. However, to effectively track the progress of each suggestion over time without resorting to risky and intensive UPDATE queries, I’ll employ a combo of history and a current table. When a new suggestion comes in, it is first stored in the history table. As updates occur, we capture the progression in the history table and reflect the current status in the dedicated current table. This way, we maintain a comprehensive record of the suggestions’ history while ensuring efficient updates. Below is what this data flow looks like.
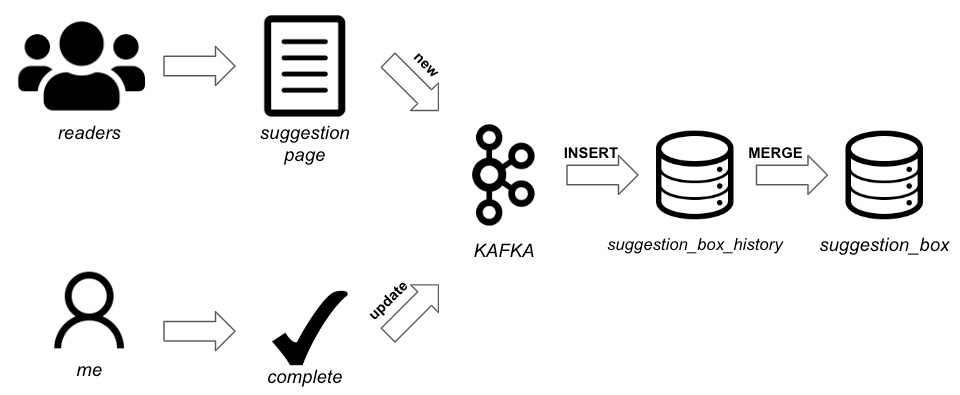
Lastly, let’s think about what the data looks like in our suggestion_box table. We’ll need an ID to uniquely identify suggestions. Additionally, at least one personally identifiable information(PII) attribute to identify the user. To track the progress, a status field that’s initially set to ‘NEW,’ which we update to ‘COMPLETE’ later. Finally, a timestamp for each suggestion and the suggestion text itself. Here’s a glimpse of our suggestion_boxtable:
+-----+----------+-------+------+-----------+-------+------------+------+
| id | timestamp| first | last | email | phone | suggestion |status|
+-----+----------+-------+------+-----------+-------+------------+------+
| 101 | 1/1 12:00| xyz | pqr |xyz@xyz.com| 555.. | crypto .. | NEW |
| 102 | 1/1 17:00| abc | mno |abc@aol.com| - | more blogs | NEW |
| 103 | 1/2 06:00| def | bcd | - | 777.. | AI blogs | NEW |
| ... | ... | ... | ... | ... | ... | ... | ... |
+-----+----------+-------+------+-----------+-------+------------+------+Data design: The “how-to”
But how do we do this with code? Here are the major steps:
Read the JSON message from Kafka: Before diving into the code, make sure to set up your Kafka server and create a topic where the suggestions page will post messages. We’ll focus on the data handling aspect using PySpark. Below is an example of how you can use PySpark to read Kafka messages into a DataFrame.
# Read messages from Kafka topic
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", kafka_topic) \
.option("startingOffsets", "latest") \ #only picks new messages
.load() \
.toDF("json")
# Define schema for JSON message
# We enforce the schema to avoid surprises with fields
schema = StructType().add("id", "string")
.add("timestamp", "timestamp")
.add("first_name", "string")
.add("last_name", "string")
.add("email", "string")
.add("number", "string")
.add("suggestion", "string")
.add("status", "string")
# Parse JSON and expand into individual columns
df = df.select(from_json(df.json, schema).alias("data")).select("data.*")
# Write to a stage table hereAdd messages to the history table: To ensure efficient querying and improved performance, it is crucial to partition the history table by a date field. This allows users to easily retrieve data based on specific time periods. Below is how you’d write it to BigQuery.
# Write it to a BigQuery history table
df = df.withColumn(
"date",
date_format(col("suggestion_timestamp"), "yyyy-MM-dd")
)
df.write\
.mode("append")\
.partitionBy("date")\
.format("bigquery")\
.save("suggestion_box_history")History to current: The current table holds only the latest data for each suggestion ID, specifically the most recent status. To manage this, we utilize the MERGE operation in SQL, which combines the INSERT and UPDATE operations into a single statement.
MERGE INTO suggestion_box AS target
USING (
-- New suggestions from history
SELECT *
FROM suggestion_box_history
WHERE date = CURRENT_DATE()
) AS source
-- Matched on suggestion's ID
ON target.id = source.id
-- To update status & timestamp
WHEN MATCHED THEN
UPDATE SET
target.status = source.status,
target.timestamp = source.timestamp
-- When no match then insert new suggestions
WHEN NOT MATCHED
THEN INSERT (
id, timestamp, first_name, last_name, email, phone, suggestion, status,date
)
VALUES (
id, timestamp, first_name, last_name, email, phone, suggestion, status,date
)User identification: Avoid bots + prioritize fans
The final part of our solution will be to add user identification, this will entail identifying the user making the suggestion. This helps me filter out spam or bot requests and prioritize requests from my fans (here’s how I identify fans). To begin, we leverage the PII info provided by the user, such as their email or phone number. We tie this information back to our user_profile table, which contains a wealth of user data, including their user_id. This allows us to determine if the user is a fan or a new user.
+------+---------+-----------+------+-------------+------+---------+----+
| date | user_id | profile_id| type | email | phone| fan_ind | ...|
+------+---------+-----------+------+-------------+------+---------+----+
| 1/1 | 123 | xyz | WEB | - | - | Y | ...|
| 1/9 | 123 | pqr | MAIL | abc@aol.com | - | - | ...|
| 1/10 | 456 | rrr | WEB | - | 777..| N | ...|
| 1/25 | 789 | ttt | MAIL | ttt@aol.com | 777..| Y | ...|
| ... | ... | ... | ... | ... | ... | ... | ...|
+------+---------+-----------+------+-------------+------+---------+----+However, it’s essential to consider the potential challenges and pitfalls when working with user data. For instance, what if a reader chooses not to provide their information and enters a fake email address like “xyz@xyz.com”? In such cases, we need a robust mechanism to handle scenarios where suggestions do not match any users or map to multiple users in the profile table due to common fake email addresses. Here’s an example of SQL that addresses this:
-- Stage table with new suggestions read from Kafka
WITH suggestions AS (
SELECT id, email, phone
FROM suggestion_box_stage
),
-- User profiles with email & phone
profile AS (
SELECT user_id, email, phone
FROM user_profile
WHERE email IS NOT NULL
OR phone IS NOT NULL
),
-- Match suggestions to users
-- Only match a suggestion if it's associated with <5 users
-- Email:
suggestions_to_match_email AS (
SELECT s.id
FROM suggestions s JOIN profile p
USING(email)
GROUP BY s.id
HAVING COUNT(DISTINCT p.cust_id) < 5
),
-- Phone:
suggestions_to_match_phone AS (
SELECT s.id
FROM suggestions s JOIN profile p
USING(phone)
GROUP BY s.id
HAVING COUNT(DISTINCT p.cust_id) < 5
),
-- Specific suggestions matched with profiles
suggestions_x_users AS (
SELECT id, user_id, fan_ind
FROM suggestions
JOIN suggestions_to_match_email
USING(id)
JOIN user_profile
USING(email)
UNION DISTINCT
SELECT id, user_id, fan_ind
FROM suggestions
JOIN suggestions_to_match_phone
USING(id)
JOIN user_profile
USING(phone)
),
-- User details in an array field
user_detail_array AS (
SELECT id,
-- arrays with multiple values for one row
ARRAY_AGG(STRUCT(user_id, fan_ind)) AS user_details
FROM (
SELECT id, user_id,
-- aggregate fan_ind: MAX to prioritize 'Y' over 'N'
MAX(IFNULL(fan_ind, "N")) AS fan_ind
FROM suggestions_x_users
GROUP BY id, user_id
)
GROUP BY id
)
-- Final suggestion ID with user details
SELECT id, user_details
FROM suggestions
LEFT JOIN user_detail_array
USING(id)Let’s break down this query, first, we identify suggestions that match a finite number(<5) of users based on either email or phone. Next, we fetch the corresponding user info for these suggestions from user_profile. Finally, to add it to the suggestion_box in an efficient manner, I pack these as an ARRAY called user_details that allows multiple values for a single row. Here’s what the output from this looks like:
+---------------+---------------------+---------------------+
| suggestion_id | user_detail.user_id | user_detail.fan_ind |
+---------------+---------------------+---------------------+
| 101 | - | - |
| 102 | 123 | Y |
| 103 | 456 | N |
| | 789 | Y |
| ... | ... | ... |
+---------------+---------------------+---------------------+As we see suggestion #101 didn’t match with any user or matched with too many users and hence the user_details are NULL, #102 matched with a fan, and #103 matched with two users of which one is a fan.
Finally, if you recollect from here, we know our knowledge of users keeps evolving and the user_id may change as a result. So the question arises should we also change our suggestion_box table to reflect this? Now the best-case scenario is to update this table however is that worth it if I’m using it to identify fans? Also, on the contrary, a reader may evolve into a fan tomorrow but I want to prioritize their suggestion considering their status at the time they make the request and hence the user_details wouldn’t change. In terms of architecture, this step sits right between reading the data from Kafka and the history table.
TL;DR
Let’s summarize what we’ve covered today:
Explored the challenge of capturing continuous reader feedback and devised a data solution for a “suggestion box” on my blog.
Looked into Apache Kafka as a streaming platform to capture suggestions and store them in a database for analysis.
Designed a data architecture with history and current tables to track suggestion progress and avoid heavy update operations.
Leveraged SQL to identify users making suggestions to prioritize requests, and avoid bots.
Demonstrated the use of arrays in SQL to efficiently store and manage user details for suggestions, enabling effective analysis and reporting.
Food for thought
Why is the ID field in these tables a string even though they’re a number like “123”? Think about nominal and ordinal variables.
How can we further enhance the suggestion box functionality? Consider things like using sentiment analysis to gauge a suggestion’s sentiment and prioritize those that align with positive sentiments.
How can we measure the impact of implemented suggestions on the blog’s success? Think about relevant metrics and how we’d track this.

Let me know how you’d approach it. If you found this helpful, share it. If you’re into this, you can find me on Twitter @abhishek27297 where I talk data.If you don’t want to miss my next post, consider subscribing here, it’s free and you’ll be notified when I post my next blog.